まず、ウィンドウズでもマックでもそうですが、数多くの機能を詰め込んでいるためシステムが重く、起動終了に時間がかかり、途中でフリーズするなどCPUのパワーの低いマシンでは非常にストレスがたまるということです。現状で使用しているマシンはペンティアム133MHz、メモリ40Mのマシンですが、一度終了してしまうと再起動に時間がかかったり、再起動中に失敗することも間々あります。それが、『超漢字』では15秒くらいで即起動し、終了は瞬時に済みます。使い始めということもあるかもしれませんが、大きなファイルの読み込み時以外はそれほど待たされることがなく、ちょっとした作業ならばウィンドウズを立ち上げる時間ぐらいで終了してしまう感があります。
更に、特徴として漢字を含む約13万字に全てコードを当て、テキスト化しているという点です。これは、国産のOSとして開発していたBTRONだからなしえた技でしょう。もともとパソコンはアメリカの技術で、文字についても最初はアルファベットのサポートしか考えられていなかったのです。それは国内で使うだけなら当然の選択で、同じものを日本で使うということなら、日本にあったOSの開発が急務であったはずなのです。しかし、キーボードの形状を含めて日本語化の努力のあとが私にとっては見えないまま、これだけパソコンが普及してしまったように見えます。キーボードについては別の場所で書く機会があるかと思いますのでここでは触れませんが、扱える漢字の数があまりにも少ないという現場に満足していない人が多いのも事実です。
JISコード第一第二水準の漢字が現在ほとんどのパソコンで使える標準になっていますが、たかだか7000字弱です。ウィンドウズ98ではこの他に補助漢字が使えるようになりましたが、日本語と入っても現在私たちが使っている漢字だけを網羅してそれでいいというわけでは決してありません。特にパソコンで電子ファイル化するのなら、過去に日本に入ってきた万葉仮名の時代から、仏教上の梵字など、考えられるありとあらゆる字体を網羅していかないと過去の遺産を電子化することはできません。過去の資料なら画像化して保存すればいいやとおっしゃる方もいるかもしれませんが、一つのファイルとしての情報量の多さ、情報の加工のしやすさという点ではテキスト化した方が便利に決まっています。このように普通の文章の中に挿入することだってできます。『超漢字』では、大漢和辞典に収録されている5万語をはじめ、他の国の言語、特に同じ漢字文化圏のなかの中国・韓国・ベトナムなどの漢字も網羅しています。今後バージョンアップを繰り返すことによって、更に扱える漢字の数は増えるてしょう。自分で書いて印刷するということならば、ウィンドウズ上で外字フォントを高い金を出して入れるよりも少ない投資で更に多くの文字を扱うことができる。これが購入の決定的な動機でした。
さて、それではいよいよ導入について具体的に書いていくことにします。ハードディスクを分割し、その領域に『超漢字』をインストールするのですが、ハードディスクを分割するにはFDISKで一旦ハードディスクを初期化してから分割するのが一般的です。しかし、やった経験のある方ならわかるでしょうが、一度初期化したハードディスクを以前の状態に戻すには非常に時間がかかります。それ以外にやりようがないというのなら、インストールを諦めてしまうかもしれないめんどくささです。そうした手間をかけなくてもハードディスクを分割できるフリーソフト『FIPS』が付属しています。というわけで私もまずインストールの前にこのソフトで分割を試みました。
まず、十分分割実績のあるソフトでも万が一データが消失してしまったらまずいので、バックアップを取ります。これは常にもう一台のパソコンにデータ関係のバックアップは取っていたので、次に進みます。
次はハードディスクをフラグメントする事です。マニュアルではシステムツールの『デフラグ』でとありましたが、それより高機能のNortnUtility『SpeedDisk』を使用しました。その後、改めて『FIPS』を起動します。しかし、これからが苦難の連続でした。
なぜかはわからないのですが、途中で作業が中断されてしまい、それ以上続行できないのですね。また、『FIPS』は国産ソフトではないのでReadMeも英語でほとんどわからないという。しかし、よーくファイルの中を見たら、このReadMeファイルを日本語に翻訳したファイルがあったのです。それを読んだら原因が分かりました。
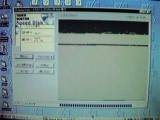 この画面は当時のハードディスクの様子です。黒いところが何らかの情報が読み込まれているところです。ちなみに、ハードディスクは4.8GBで、使用領域は1GB弱といったところ。ちょっと見えにくいですが、一番下の部分に注目してください。全体的に上にデータが集中しているのですが、一番下の部分にも黒いものがあります。この部分が、新しく区画を作るためにはそれを閉ざす蓋のような役目をしているらしく、この部分を先頭に移動させない限りは分割できないことがわかりました。
この画面は当時のハードディスクの様子です。黒いところが何らかの情報が読み込まれているところです。ちなみに、ハードディスクは4.8GBで、使用領域は1GB弱といったところ。ちょっと見えにくいですが、一番下の部分に注目してください。全体的に上にデータが集中しているのですが、一番下の部分にも黒いものがあります。この部分が、新しく区画を作るためにはそれを閉ざす蓋のような役目をしているらしく、この部分を先頭に移動させない限りは分割できないことがわかりました。それにしても、原因は分かったもののそれをどうやって解決していくのか。マニュアルにはデータの属性を変えてと書いてありました。具体的なファイルの名前『image.idx』を検索によって見つけだし、改めてスタートメニューから『MS-DOSプロンプト』を開きます。そこでマニュアル通り属性を変え、これで大丈夫かと思ったのですが、以前としてうまくいかず、残ったデータを見てみると、これが一連のATOKに関するファイルだったのです。
これには本当に参りました。結局様々なことを実行してみたものの写真のような状況は変わらず、『FIPS』を実行しても中断するばかり。ここでその日の作業は中断し、頭を冷やすことにしました。
次の日、原点に戻れということでフラグメントにシステムツールの『デフラグ』を使ってみました。そうしたら何と、スムーズにハードディスクが分割できたではありませんか(^^;)。教訓として、マニュアルには忠実であれということを再確認した次第です。
次にハードディスクにどれくらいの領域を割り当てたらいいのかということですが、漢字を最大限に使うためには最大構成のインストールが必須で、システムに300、ユーザー用に最低100、合計400以上と書かれています。空きだけはあったのですが、ウィンドウズの方に今後いろいろ入れる事も考えて約700メガを割り当てました。いよいよインストールです。
インストールの方法は4種類ありますが、付属CD-ROMからフロッピーディスクを作って登録する方法は最小構成だけに限られるため、実質は三種類といってもいいでしょう。一番目の方法はCD-ROMから直接登録する方法ですが、私の機種だとSCSI接続で、ブートは不可能なのでこの方法ではできません。しかし、そういうときのために、パッケージには起動フロッピーディスクが付属しています。機種によっては二番目の方法、フロッピーで起動、CD-ROMから読みとりという方法もあったのですが、私は三番目の方法を取りました。
その方法とは、まずウィンドウズの入っているCドライブに『超漢字』のデータ全てをコピーします。最大構成ですと全部で150M必要になりますが、十分空きのある私のハードディスクにとっては全く問題ありませんでした。コピーしたら改めてフロッピーから起動させ、登録作業を行うのです。これだとCD-ROMとフロッピーが同時に使えないようなノートパソコンでもインストール可能なのが嬉しいですね。というわけで、二日間かけてやっと導入が完了しました。はっきり言って思いっきり疲れましたね(^^)。(99.11.20)